Pipelining
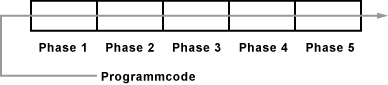
Die Befehlsausführung in einem Prozessor erfolgt wie an einem Fließband (Pipeline). Eine Pipeline ist eine Abfolge von Verarbeitungseinheiten, die einen Befehl ausführen. Wenn ein Befehl von Phase 1 seiner Bearbeitung in Phase 2 tritt, betritt der nächste Befehl Phase 1. Die Bearbeitung in jeder Phase dauert im Optimalfall einen Taktzyklus.
Die Pipeline-Verarbeitung kommt in CISC-CPUs zum Einsatz, da dort die Befehle so komplex sind, dass ihre Bearbeitung innerhalb eines Taktzyklusses nicht möglich ist.
Beispiel für eine 5-Phasen-Pipeline
- Fetch: Befehl holen/laden
- Decode: Befehl dekodieren
- Load: Operanden laden
- Execute: Befehl ausführen
- Write: Ergebnis schreiben
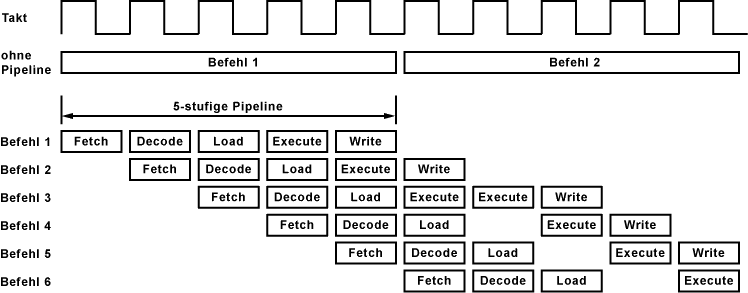
Im oberen Beispiel besteht die Pipeline zur Befehlsbearbeitung aus 5 Stufen bzw. Phasen. Innerhalb der Pipeline wird versucht alle Stufen gleichzeitig für aufeinanderfolgende Befehle zu nutzen. In diesem Beispiel benötigt der dritte Befehl zwei Taktzyklen für die Execute-Phase. Die nachfolgenden Befehle müssen warten. Die Bearbeitung in der Pipeline kommt ins Stocken.
Bei Desktop-Prozessoren ist es üblich, die Pipeline zu verlängern.
Doch weniger Pipeline-Stufen haben insbesondere dann einen Vorteil, wenn im Programmcode häufig unvorhergesehene Sprünge zu einer anderen Stelle im Programmcode erfolgen. Bei einem Sprung im Programmcode muss eine Pipeline komplett geleert werden. Die bereits erfolgten Berechnungen sind überflüssig. In einer langen Pipeline wären das sehr viele Berechnungen. In einer kurzen Pipeline macht ein unvorhergesehener Sprung nicht so viel aus. Um trotzdem eine lange Pipeline realisieren zu können, setzt man auf eine spekulative Sprungvorhersage. Die Sprungvorhersage könnte zum Beispiel ein Teil einer vorgelagerten Pipeline sein.
Superskalarität

Zur Bearbeitung eines Befehls ist meistens nur eine bestimmte Einheit eines Prozessors beschäftigt. Andere Einheiten bleiben ungenutzt. Wenn die Befehle eines Programms in geeigneter Reihenfolge auf zwei oder mehr Pipelines aufgeteilt werden und diese unabhängig voneinander arbeiten (skalar) können, entsteht eine parallele Ausführung.
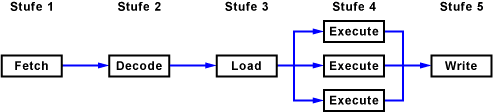
Sind von einer Ausführungseinheit gleich mehrere vorhanden, spricht man von Superskalarität.
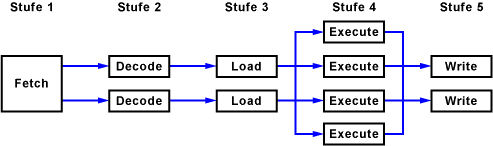
Moderne Prozessoren verwenden meist eine Kombination aus mehreren Pipelines und Ausführungseinheiten.
Beispiel für eine Pipeline mit L1- und L2-Cache
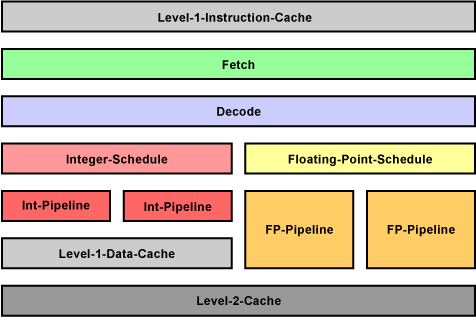
In-Order-Execution
Mit einfachen Heuristiken prüft der Prozessor, ob zwei aufeinanderfolgende Befehle parallel ausgeführt werden können. Wenn ja, dann werden sie in zwei Pipelines abgearbeitet. Für spezielle Befehlsgruppen gibt es sogar eigene Pipelines.
Wenn ein Befehl früher fertig ist als der Befehl in der anderen Pipeline, dann wartet er, bis auch der andere abgearbeitet ist. Erst dann geht es im Programmcode weiter. Der Compiler kann durch geschickte Sortierung der Befehle für eine Optimierung sorgen. Wenn dann aber ein Befehl auf den Speicher zugreift und die Daten nicht in einem der Caches sind, dann muss der Prozessor warten. An dieser Stelle hätte eine Out-of-Order-Execution klare Vorteile. Hier treten Wartezeiten seltener auf.
Out-of-Order-Execution
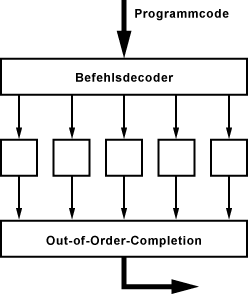
Bei superskalaren Prozessoren ist die Leistungssteigerung im wesentlichen von der Auslastung der parallel arbeitenden Ausführungseinheiten abhängig. Dabei kann es vorkommen, dass ein Befehl, der im Programmcode nach einem Befehl steht, noch vor diesem aufgeführt wird. Das hätte zur Folge, dass Operationen, die im Programmcode eigentlich erst später folgen sollten, vorgezogen werden könnten, wenn gerade Rechenleistung frei ist. Diese Technik nennt man Out-of-Order-Execution.
Ein Teil der Out-of-Order-Execution ist die Out-of-Order-Completion. Die Out-of-Order-Completion ist ein spezieller Mechanismus, der sicherstellt, dass das Ergebnis dem entspricht, was bei einer sequentieller Bearbeitung herauskommen würde.
Sprungvorhersage (Spekulation)
Richtig effizient ist die Out-of-Order-Execution erst dann, wenn sie spekulieren (Sprungvorhersage) kann. Dann nämlich kann sie versuchen den Programmcode vorherzusehen und Befehle vorzeitig ausführen, um später das Ergebnis zum Einsatz zu bringen.
Die Sprungvorhersage beruht im einfachsten Fall auf statistischen Erkenntnissen. Rückwärtssprünge im Programmcode finden oft am Ende von Schleifen statt. Während bedingte Vorwärtssprünge meistens nicht statt finden.
Trifft die Sprungvorhersage (Spekulation) nicht zu, dann muss der Prozessor das Ergebnis verwerfen und am letzten sicheren "Checkpoint" von vorne anfangen. Trifft die Sprungvorhersage zu, dann hat das einen regelrechten Geschwindigkeitsschub zur Folge. Die Hardware für die Spekulation verbraucht leider sehr viel Energie.